大模型+知识库部署学习1
这篇blog主要是对大模型部署(chatglm2-6b)的一些学习。该部署还结合了向量数据库,一定程度上实现了RAG。
网页资料
LangChain + ChatGLM2-6B 搭建个人专属知识库 - 知乎 (zhihu.com)
LangChain结合milvus向量数据库以及GPT3.5结合做知识库问答之二 —>代码实现-CSDN博客
【Langchain实战】基于langchain和向量数据库解决语料库超过GPT 4k tokens的问题 - 知乎 (zhihu.com)
chatglm2外挂知识库问答的简单实现_相国的博客-CSDN博客
Milvus,Faiss,chromadb
笔记︱几款多模态向量检索引擎:Faiss 、milvus、Proxima、vearch、Jina等 - 知乎 (zhihu.com)
docker 安装
[Docker安装配置详细步骤【图解】_>>> 安装配置 docker 1. 安装 docker 开始下载 docker 程序 … e-CSDN博客
windows milvus安装
windows搭建向量数据库milvus_milvus windows-CSDN博客
Windows系统本地部署向量数据库milvus_milvus windows_Joeybee的博客-CSDN博客
windows安装向量数据库milvus_milvus windows-CSDN博客
langchain+Milvus
用Milvus和Xinference本地搭建基于Llama 2-70B的问答系统 - 知乎 (zhihu.com)
milvus安装及其使用教程_milvus使用-CSDN博客
实战1
langchain+chatglm2-6B+faiss
项目参考链接:thomas-yanxin/LangChain-ChatGLM-Webui: 基于LangChain和ChatGLM-6B等系列LLM的针对本地知识库的自动问答 (github.com)
项目流程
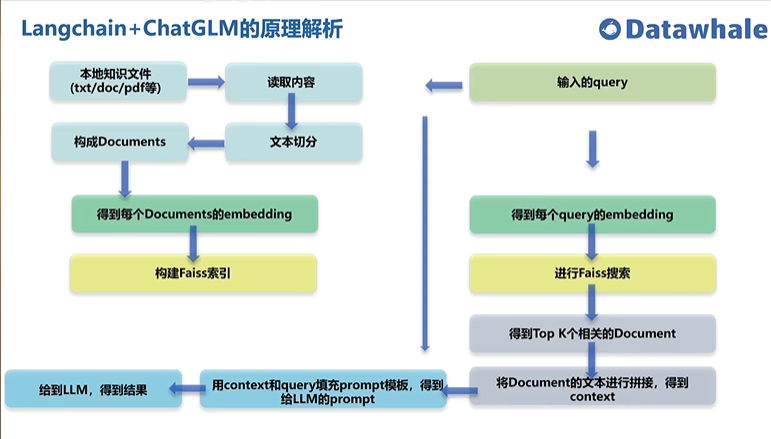
要求:项目需要Python>=3.8.1, 默认已安装torch,cuda版本高一点比较好
注意
- 安装faiss注意
- 正常流程安装faiss,官网conda install -c pytorch faiss-cpu,我用的是pip install faiss-cpu
- 但是numpy的班恩不能为1.26.0,我用的是1.22.4
- 否则会报:ImportError: DLL load failed while importing _swigfaiss: 找不到指定的模块。
- pip requirement时注意事项:
需要对gradio进行降级处理pip install gradio==3.10
总的流程为
- 相关文件的下载:1、langchain-chatglm-Webui;2、chatglm2-6b;3、text2word embedding编码器
- 将知识编码为向量存入到知识库中(向量数据库)
- 读取内容
- 文本切分
- embedding
- 将query编码
- 搜索
- 将检索内容+query一同作为prompt输入给llm
- LLM response
实验
环境
python 3.8,torch2.0 cuda 11.8
显卡:A5000 24G,内存30G,硬盘50
%% ssh -p 34207 root@region-8.autodl.pro
PNtiy0k3JecZ %%
上面的ssh和密码是可以变动的
- 我是先进入home目录,在home目录下
mkdir LLM,在这个文件夹里面进行相关的部署 - git clone https://github.com/thomas-yanxin/LangChain-ChatGLM-Webui.git
- 将项目文件拷贝到对应的目录中但是不知道为啥总是超时,所以利用mobalxterm手动加载进去的
- 利用wget下载embedding模型
- wget -O text2vec-chinese-base.zip ‘https://s3.openi.org.cn/opendata/attachment/0/c/0cebbcbc-5e41-4826-9052-718b601790d9?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=1fa9e58b6899afd26dd3%2F20231026%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20231026T121940Z&X-Amz-Expires=86400&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B filename%3D"text2vec-base-chinese.zip"&X-Amz-Signature=fc26e7e501d45de3beb5eebfa11c9b2dd35f18ea722d5cbd455dea79528d2284’
- -O 是下载到指定文件名
- 这里的链接一定要加英文的双引号不然会报错:‘’
- wget -O text2vec-chinese-base.zip ‘https://s3.openi.org.cn/opendata/attachment/0/c/0cebbcbc-5e41-4826-9052-718b601790d9?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=1fa9e58b6899afd26dd3%2F20231026%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20231026T121940Z&X-Amz-Expires=86400&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B filename%3D"text2vec-base-chinese.zip"&X-Amz-Signature=fc26e7e501d45de3beb5eebfa11c9b2dd35f18ea722d5cbd455dea79528d2284’
- 同样利用wget下载LLM:chatglm2-6b
- 在unzip -d text2vec-chinese-base text2vec-chinese-base.zip,LLM同理
- 将zip文件夹解压到指定文件夹中
-d选项用于指定解压缩后文件的目标目录
- 由于本电脑的git clone存在问题,换了台电脑。不知道为什么总是git clone 不了。
- 如果是在太慢了一个一个安装,将requirements.txt中的拿出来一个一个安装
遇到的问题
- gradio还是要为3.23.0,但都会遇到问题
- 得装一个frpc击穿网络?
- 【Gradio】Could not create share link-CSDN博客
- 由于wget也会失败建议windows本地建完然后上传到linux的gradio文件夹中
- 我用gradio3.10版本最后会报错:*** Failed to connect to ec2.gradio.app:22: [Errno 110] Connection timed out
- 我用gradio 3.23版本最后会是无法创建share link
- 然后waget frpc那个还无法waget请问如何结局
- 记得对frpc_linux_amd64_v0.2进行执行能力赋予 chmod +x
- 模型无法加载
- 始终无法加载
- 实验失败
chatglm2-6b 部署尝试
ssh -p 18186 root@region-8.autodl.pro
Fa+uIT7ETyJK
具体同上:先git clone 然后 wget 然后再unzip等
上述网站所提供的chatglm2的链接有一定问题,虽说可以用,但是会报错
实战2
得先安装:pip install chromadb
01_ChatGLM环境部署_哔哩哔哩_bilibili
langchain+chatglm+chroma
试试这个教程
-
大模型部署,这里作者尝试了web_demo和api,这里的实践采用的是通过chatglm api分配的本地url来进行实验
-
from langchain.llms import ChatGLM # 创建llm llm = ChatGLM( endpoint='http://127.0.0.1:8000',//api分配的url max_token=80000, top_p=0.9 ) <!--code0--> from langchain.document_loaders import DirectoryLoader from langchain.text_splitter import CharacterTextSplitter def load_documents(directory="books"): """ 加载books下的文件,进行拆分 :param directory: :return: """ loader = DirectoryLoader(directory) documents = loader.load() text_spliter = CharacterTextSplitter(chunk_size=256, chunk_overlap=0) split_docs = text_spliter.split_documents(documents) return split_docs <!--code1-->
-
存储
-
#这里用的是chorma # 加载数据库 from langchain.vectorstores import Chroma if not os.path.exists('VectorStore'): documents = load_documents() db = store_chroma(documents, embeddings) else: db = Chroma(persist_directory='VectorStore', embedding_function=embeddings) <!--code2-->
-
-
加一个web_ui,用的是gradio,简易版本
-
import gradio as gr def chat(question,history): response=qa.run(question)#这里也可以加入history return response demo = gr.ChatTnterface(chat) demo.launch(inbrowser=True) <!--code3--> 1. yeild:https://zhuanlan.zhihu.com/p/268605982 1. `yield`的函数则返回一个可迭代的 generator(生成器)对象,你可以使用for循环或者调用next()方法遍历生成器对象来提取结果。
-
-
输入是中文输出是英文+中文,这里得好好修改。langchain的prompt是英文。由于chatglm比较小,我们可以不用langchain做最后的回答,自己做最后的回答,自己去注入一些prompt。
- 还可以将一些比较好的对话搜集,作为prompt,使得模型的输出更加的稳定
额外的补充
1 | from langchain.embeddings.openai import OpenAIEmbeddings |
不同的向量数据库
faiss专注于相似性搜索,milvus除了相似性搜索还有数据库管理
1 | # milvus |
1 | #faiss |
1 | # Chroma |
笔记︱几款多模态向量检索引擎:Faiss 、milvus、Proxima、vearch、Jina等 - 知乎 (zhihu.com)
其中个人milvus使用起来相对麻烦一点,但是milvus提供了可视化的管理工具,且功能更加强大,chromadb使用起来简单,其中向量保存的文件格式为sqlite3,也可以利用数据库软件进行可视化,faiss的保存文件格式是index,没找到相关可视化软件,不太容易后期的维护。这三种数据库都支持本地部署。